Google Smartphone Decimeter Challengeの解法
Google Smartphone Decimeter Challenge
概要はこちら
post-processing approach
snap to grid (snap to ground truth)
地理情報を取得し、最寄りの位置(地理情報)に予測位置を補正する手法です。
このnotebookでは、地理情報のみのアプローチですが、trainデータとtestデータで同じ経路を通っている場所も一部あることから、trainデータのground truthもsnap対象としました。
なお、最寄りの緯度経度を見つけるのは気軽に叩けないほど時間がかかりました。
Road detection and creating grid points | Kaggle
mean predict
同じ日に集めた位置情報データには、複数のスマートフォンがある含まれていることがあるため、それを平均化するアプローチです。そのまま用いました。
GSDC phones mean prediction | Kaggle
remove outlier & kalman filter
緯度経度を外れ値を線形補間し、カルマンフィルタによる平滑化をしています。 そのまま用いました(正直カルマンフィルタのパラメータ等、さっぱりわかりませんでした)。
Baseline post-processing by outlier correction | Kaggle
adaptive gauss & phone mean
ガウシアンフィルタで、緯度経度を平滑化し、複数のスマートフォンで平均化しています。
ガウシアンフィルタは、上記のremove outlier ->kalman filter よりもLBのスコアは低い印象だったため、imu approachの入力にのみ用いました。
phone meanは上記のmean predictとは違う手法だっため、こちらも採用しました。
Adaptive_gauss+phone_mean | Kaggle
moving or not
車が停止しているとき、緯度経度の精度が著しく悪くなる傾向から、車が止まっているか動いているかを判定するモデルを作成しています。
このnotebookでは、交差検証の結果94%の精度でしたが、testデータに対して可視化した結果、精度がもう少し欲しいという印象でした。
そこで、rollingで特徴量を増やし、ベースライン等の緯度経度、そのdiffなどを特徴量として加えることで98%まで精度を上げました。 ただし、PAOなどのtrainデータにはあってtestデータにはある場所は、緯度経度を特徴量として用いていることが原因なのか、正しく予測できなかったため、除外しました。
これらの結果から、停止している中で、最も時系列的に近い値で補間しました(ほとんどの方が平均で補間しており、この手法が平均補間よりも優れているという証拠があるわけではないのであしからず)。
この辺の実装はかなりギリギリでした。
A car is Moving or Not?? Accuracy 94%! | Kaggle
positon shift
スマートフォンの設置位置と車のアンテナとの差を補正するアプローチだと思っています(正直あまり見れていないです)。
こちらもギリギリで作成してみたくらいで、深く検討できなかった後処理です。
imu approach
ベースラインの緯度経度と、IMU(加速度、ジャイロ、磁気)を加えてラグ特徴量とrolling特徴量を加え、緯度経度を予測するアプローチです。 緯度経度を直接予測するのではなく、一端XYZに変換して予測していました(これが有効であるかは試していませんが、notebook投稿者いわく、緯度経度では予測がうまくいかないが、XYZではうまくできたとのことでした)。
ここからさらに精度を上げるため、ベースラインに後処理を加えた緯度経度を入力として追加しました。
具体的には以下の位置情報を入れています。
- baseline
- imu
- baseline→remove-outlier→kalman→phone-mean ← new!
- baseline→remove-outlier→kalman→mean-predict ← new!
- baseline→remove-outlier→kalman→phone-mean->mean-predict ← new!
- baseline→remove-outlier→kalman→mean-predic->phone-meant ← new!
- baseline→adaptive-gauss→phone-mean ← new!
- baseline→adaptive-gauss→mean-predict ←new!
- baseline→adaptive-gauss→phone-mean→mean-predict ← new!
- baseline→adaptive-gauss→mean-predict→phone-mean ← new!
そこから、尖度、歪度、最大ー最小などの特徴量を加え、合計約750ほどの特徴量になりました。
trainデータとtestデータにあるデータで同じ経路を通っているのは、SJCとMTVの一部でした。そのため、この手法はその部分のみ適用させました(RWCがMTVの一部と一緒だったためこれも加えています。
Predict Next Point with the IMU data | Kaggle
solution
baselineから後処理していくアプローチと、imuから後処理していくアプローチの2つから、加重平均を計算し、提出しました。
LBのスコアからimu側を重視しました(これはプラスに働いたようです)。
非常に複雑怪奇な解法な原因は、アンサンブルをするのを最後の最後まで後回しにしてしまった結果です。 最後の3、4日くらい?
imuはLBのスコアが4.2以下、baselineはLBのスコア上位3つ、という脳死選択をしてしまいました。
後処理の順番が基本同じなのは、publicLBのスコアから判断しています。ただ、これがpublicにフィッティングし過ぎた原因かもしれません。(public22位→private34位)
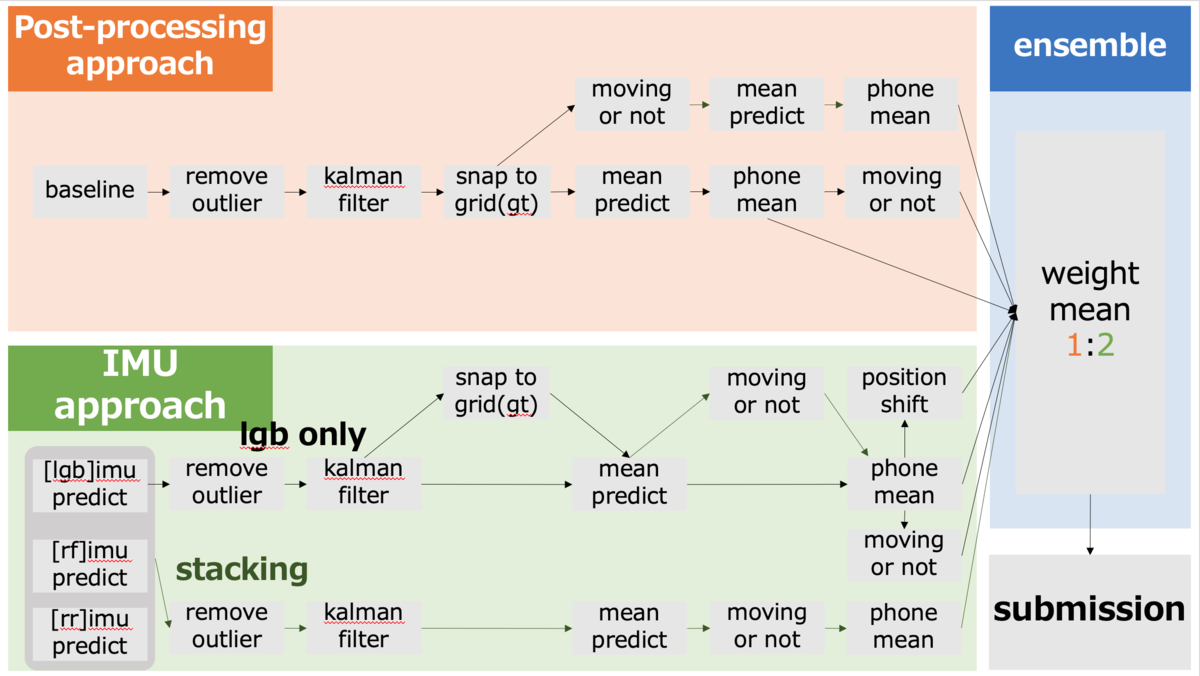
- 補足
- lgb:LihgtGBM
- rf:Random Forest
- rr:Ridge Regression