スライディングウィンドウ処理をしたIMUセンサデータに対して、クラスタリングによるパターン抽出は有効か否か
はじめに
以前、Twitterにて
前略ーー時系列データをsliding windowで切り取ってkmeansしてパターン見つけるみたいな手法あるけどそれやると正弦波になって意味ないでみたいな話を思い出したーー後略
というものを見かけました。
時系列データの前処理として、スライディングウィンドウ処理で部分時系列を作り、それを特徴ベクトルとして機械学習で予測する、みたいなことは何度も経験があるので、k-meansの中心点が正弦波(位相は問わない?)になるというのはとても興味深いです。
ツイートを見かけたときは「へー」くらいに思って、いいねしてたのですが、今回は気になったので、自分の持っているデータで調べてみることにしました。
文献としては少し古いですが、色々試してみようと思います。
データ
データは自転車の走行データを用います。
これはスマホでデータ収集しているのですが、自転車のかごに設置しております。
ポーチの中にスマホ入れております(迷彩柄のポーチは無視してください)。
具体的なデータは、IMU(加速度、ジャイロ、磁気センサ)のそれぞれXYZ、合計9軸で試してみます。
走行場所の詳細は言えませんが、私の自宅から大学間の約5kmになります。

プログラム
データ準備
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler df = pd.read_csv('2021-09-02 09.csv') df
下記がデータのサンプルです。
緯度経度などもとれますが、今回はこれらの時間(Time)を除くこれらのデータだけ試します。
| Time | Acc_X | Acc_Y | Acc_Z | Roll | Pitch | Yaw | Com_X | Com_Y | Com_Z |
|---|---|---|---|---|---|---|---|---|---|
| 2021-09-02 09:38:15 | -0.188782 | -0.530762 | -0.850571 | -0.295878 | 0.562196 | 1.688278 | -2.819519 | -11.504997 | -10.297852 |
センサは先に述べたとおり、以下のものを使います。
また、文献の通り、k=3、window=128で以降を実装していきます。
sensors = [
'Acc_X', 'Acc_Y', 'Acc_Z',
'Roll', 'Pitch', 'Yaw',
'Com_X', 'Com_Y', 'Com_Z'
]
k = 3
window = 128
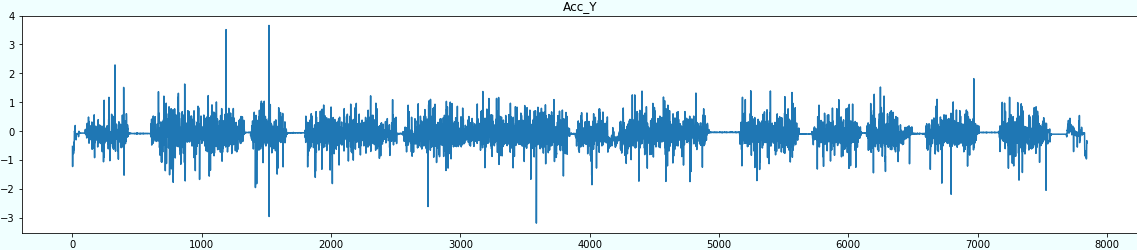
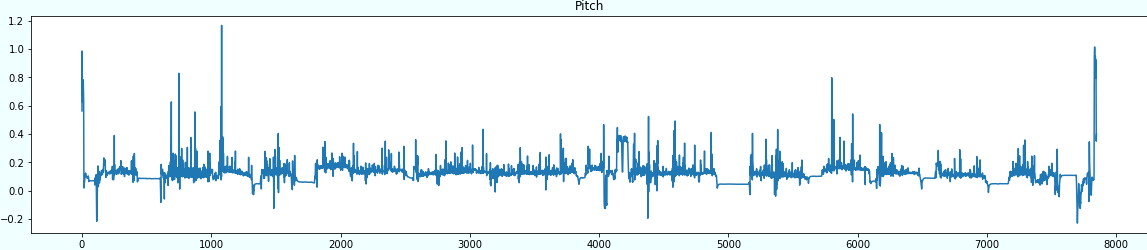
まず、全体の可視化を見てみましょう。
for sensor in sensors: plt.figure(figsize=(20,4)) plt.title(sensor) plt.plot(df[sensor]) plt.show()







クラスタリング(k-means)するので、標準化しておきます。
スケーリング大事。
def scaler(df, sensors): scaler = StandardScaler() arr = scaler.fit_transform(df[sensors]) df_std = pd.DataFrame(arr, columns=sensors) return df_std df_std = scaler(df, sensors)
部分時系列を作成します。
文献と同じくウィンドウサイズ128とし、1ステップずつwindowをずらしていきます。
def make_subsequences(df, sensor): vec = df[sensor].values return np.array([vec[i:i+window] for i in range(len(vec)-window+1)])
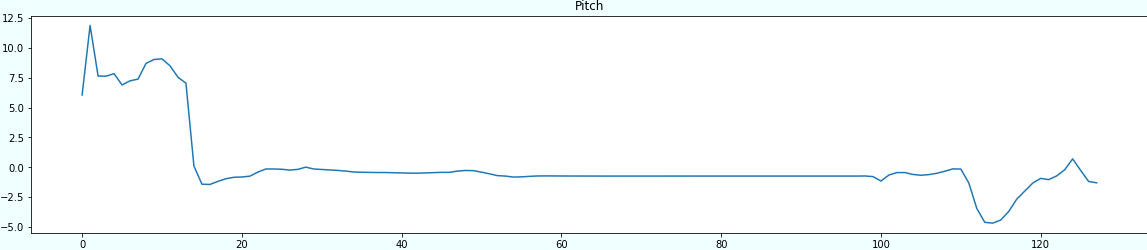
部分時系列の初めだけを可視化するのと、以下のようになります。
for sensor in sensors: plt.figure(figsize=(20,4)) plt.title(sensor) subsequences = make_subsequences(df_std, sensor, window) plt.plot(subsequences[0]) plt.show()








クラスタリング
いよいよ本番です。
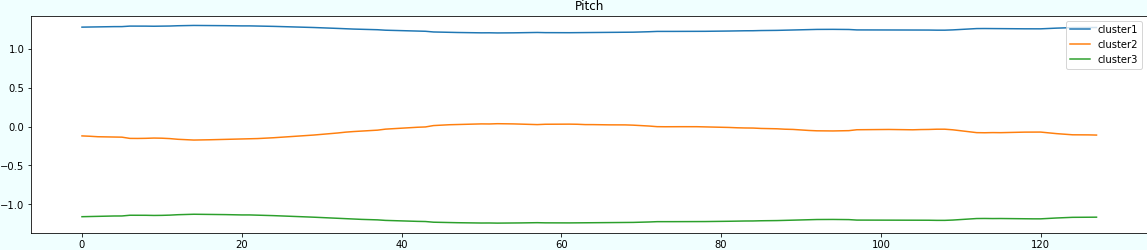
文献の通りk=3としてクラスタリングをし、中心点をクラスタごとに色分けして可視化してみます。
なお、中心点のデータサイズが異なるため、可視化用にスケーリングしてます(可視化結果を見やすくするためです)。
kmeans = KMeans(n_clusters=k, random_state=2021) scaler = StandardScaler() for sensor in sensors: subsequences = make_subsequences(df_std, sensor, window) kmeans.fit_predict(subsequences) centers = scaler.fit_transform(kmeans.cluster_centers_) plt.figure(figsize=(20,4)) plt.title(sensor) plt.plot(centers[0], label='cluster1') plt.plot(centers[1], label='cluster2') plt.plot(centers[2], label='cluster3') plt.legend(loc='upper right') plt.show()








結果
結果をまとめると以下のような感じでしょうか。
完全主観にはなりますが、Acc_XやRollはかなり正弦波ぽいですね。
| sensor | result |
|---|---|
| Acc_X | 正弦波ぽい |
| Acc_Y | あやしい |
| Acc_Z | あやしい |
| Roll | 正弦波ぽい |
| Pitch | 平ら |
| Yaw | 平ら |
| Com_X | 正弦波ぽい |
| Com_Y | 正弦波ぽい |
| Com_Z | 平ら |
データ数増やして再チャレンジ
往々にして、データサイエンス分野はデータない問題とデータ足りない問題が、結果の原因となります。
今回は、データはそこそこ持っているので、脳筋戦法ということで増やしてみました。
Before
- 2021-09-02 09
- レコード数は7848
After
- 2021-05-28 21~2021-09-02 09(毎日ではない)
- レコード数は762744
さて、いざ尋常に......!!
各日の走行データを結合します。
後の処理のためにIDを振っておきます。
from glob import glob path_list = glob('data/*') new_df = pd.DataFrame() for i, path in enumerate(path_list): df = pd.read_csv(path) df['ID'] = i new_df = pd.concat([new_df, df], axis=0) new_df = new_df.reset_index(drop=True)
先ほどと同様スケーリングし、IDだけをスケーリング後のdfに結合します。
これで準備は整いました。
new_df_std = scaler(new_df, sensors) new_df_std = pd.concat([new_df_std, new_df[['ID']]], axis=1)
dfをIDごとに抽出し、一回の走行の部分時系列(one_subsequences)を作成します。
これを全体の部分時系列(subsequences)として、結合していきます。
毎回抽出して結合しないと、まったく関係ない日の走行データ同士で部分時系列を作ってしまうので、こんな処理してます。ちょっと面倒ですね。
kmeans = KMeans(n_clusters=k, random_state=2021) scaler = StandardScaler() for sensor in sensors: subsequences = np.empty((0, window)) for i in range(new_df_std['ID'].max()+1): one_df = new_df_std[new_df_std['ID']==i] one_subsequences = make_subsequences(one_df, sensor, window) subsequences = np.append(subsequences, one_subsequences, axis=0) kmeans.fit_predict(subsequences) centers = scaler.fit_transform(kmeans.cluster_centers_) plt.figure(figsize=(20,4)) plt.title(sensor) plt.plot(centers[0], label='cluster1') plt.plot(centers[1], label='cluster2') plt.plot(centers[2], label='cluster3') plt.legend(loc='upper right') plt.show()







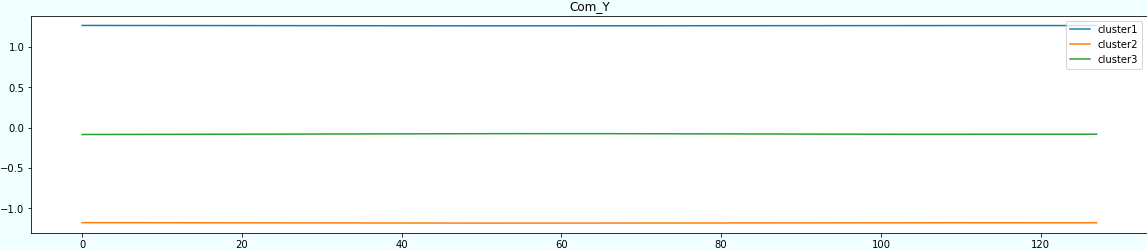

結果2
先程より全体的に平らになりましたね。
ただ、Acc_Yがかなり正弦波ぽくなりました。
面白いのがAcc_Zですね。重力の影響なのか、自転車なので段差などの影響によりノイズが多いのかわかりませんが、細かい波形になっています。
| sensor | result | result2 |
|---|---|---|
| Acc_X | 正弦波ぽい | 平ら |
| Acc_Y | あやしい | 正弦波ぽい |
| Acc_Z | あやしい | あやしい |
| Roll | 正弦波ぽい | 平ら |
| Pitch | 平ら | 平ら |
| Yaw | 平ら | 平ら |
| Com_X | 正弦波ぽい | 平ら |
| Com_Y | 正弦波ぽい | 平ら |
| Com_Z | 平ら | 平ら |
考察
今回は文献の通りk=3でクラスタリングしています。そのため、各センサにつき3パターンにグルーピングしていることになります。
果たして3パターンだけでしょうか。全体の可視化結果から見るに、3パターンよりも多そうです。
今回うまく正弦波になっていないセンサは、それが原因の可能性もあるかもしれません。
どちらにせよ、はじめにの「時系列データをsliding windowで切り取ってkmeansしてパターン見つけるみたいな手法」による特徴は、IMUでも有効ではなさそうです。
まとめ
Twitterで見かけた手法を、私が趣味で集めていた自転車の走行データ(IMU)で試してみました。
実際にいくつか正弦波ぽくなり、大変勉強になりました。
実装等で間違いがあれば、教えていただけれると幸いです。