カテゴリ変数(質的データ)の前処理の違いまとめ
はじめに
一般的に機械学習においてカテゴリ変数は、前処理として数値化する必要があります。
本記事ではその前処理の方法と違いについてまとめです。
データの種類と意味
下図のように変数は4つの尺度に分けられます。
今回説明するのは名義尺度と順序尺度に関する前処理の方法です。

データ
まず、簡単なデータを以下のコードで準備します。あるユーザがある飲み物を買ったときの値段、サイズ、飲み物の種類が記載されています。
このデータでは、sizeデータはL>M>Sの関係にあるため順序尺度、drinkデータは大小関係がないため名義尺度になります。
import numpy as np import pandas as pd df = pd.DataFrame([ ['Aさん', 100, 'S', 'cola'], ['Bさん', 150, 'M', 'tea'], ['Cさん', 200, 'L', 'coffee'], ['Dさん', 100, 'S', 'tea'], ['Eさん', 200, 'L', 'coffee'], ['Fさん', 200, 'L', 'tea'], ['Gさん', 150, 'M', 'tea'], ['Hさん', 200, 'L', 'coffee'], ['Iさん', 100, 'S', 'cola'], ['Jさん', 200, 'L', 'tea']], columns=['user', 'price', 'size', 'drink']) df

前処理の種類と違い
一般に2つのアプローチがあります。
1つ目は順番にラベリングしていく方法です。colaを0、teaを1、coffeeを2のようにラベルをつけます。
2つ目はダミー変数化(OneHotエンコーディング)する方法です。cola、tea、coffeeのカラムを新しく追加し、任意のカラムを1、それ以外のカラムを0にします。
1つ目の方法は決定木ベースのモデルには効果はありますが、線形モデルやNNに使う場合は注意が必要です。「teaはcoffeeと2倍の関係にある」といった解釈をされかねません。
2つ目の方法は1つ目より使われる気がします。ただし、カテゴリ変数が1000個あるといったふうに、量が多ければ多いほどカラムも増えます。膨大なカテゴリ変数は適宜集約するといった処理が必要になるかと思います。
名義尺度
ラベリング
factorize
pandasのfactorizeを使えば、簡単にカテゴリ変数をラベリングしてくれます。
ft_array, ft_index = pd.factorize(df['drink']) # tupple型で返却される df_ft = pd.DataFrame(ft_array, columns=['ft_drink']) df_factrize = pd.concat([df, df_ft], axis=1) # 元のデータフレームと連結 df_factrize

LabelEncoder
sklearnのLabelEncoderを使えば、簡単にカテゴリ変数をラベリングしてくれます。
from sklearn.preprocessing import LabelEncoder lenc = LabelEncoder() lenc.fit(df['drink']) lenc_vec = lenc.transform(df['drink']) df_le = pd.DataFrame(lenc_vec, columns=['le_drink']) df_lenc = pd.concat([df, df_le], axis=1) # 元のデータフレームと連結 df_lenc

factorizeとLabelEncoderの違い
以下のように学習データとテストデータに分けられたデータがあるとします。
Nさんが学習データにはないサイズと飲み物の種類(LLとcider)が記載されていることに注意してください。
train = df.copy()
test = pd.DataFrame([
['Kさん', 200, 'L', 'cola'],
['Lさん', 100, 'S', 'tea'],
['Mさん', 150, 'M', 'coffee'],
['Nさん', 250, 'LL', 'cider']],
columns=['user', 'price', 'size', 'drink'])
factorizeは値の出現順にラベルが振られるため、データフレームが別々にある場合、別のラベルが振らてしまう可能性があります。
train_ft, idx = pd.factorize(train['drink']) test_ft, idx = pd.factorize(test['drink']) train_df = pd.concat([train, pd.DataFrame(train_ft, columns=['ft_drink'])], axis=1) test_df = pd.concat([test, pd.DataFrame(test_ft, columns=['ft_drink'])], axis=1) display(train_df) display(test_df)

一度trainデータとtestデータを連結させ、1つのデータフレームとしてラベルを振れば回避することができます。
all_df = pd.concat([train, test], axis=0).reset_index(drop=True) all_ft, idx = pd.factorize(all_df['drink']) train_test_df = pd.concat([all_df, pd.DataFrame(all_ft, columns=['ft_drink'])], axis=1)
しかし、kaggleのようにあらかじめ学習データとテストデータがわけられている場合、わざわざ連結するのは面倒です。LabelEncoderを使えば連結せずに済みます。
なお、ラベリングの順番はfactorizeは値の出現順ですが、LabelEncoderはアルファベット順です。名義尺度のデータでは、ここはあまり気にする必要はないかと思います。
lenc = LabelEncoder() train_df = lenc.fit(['cola', 'tea', 'coffee', 'cider']) # ここでカテゴリ変数の種類を指定 train_lenc = lenc.transform(train[['drink']]) test_lenc = lenc.transform(test[['drink']]) train_df = pd.concat([train, pd.DataFrame(train_lenc, columns=['le_drink'])], axis=1) test_df = pd.concat([test, pd.DataFrame(test_lenc, columns=['le_drink'])], axis=1) display(train_df) display(test_df)

ダミー変数化
get_dummies
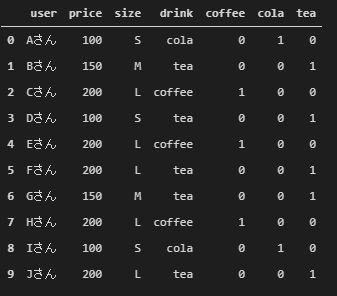
pandasのget_dummiesを使えば、簡単にカテゴリ変数をダミー変数化してくれます。
df_gd = pd.get_dummies(df['drink']) df_dummy = pd.concat([df, df_gd], axis=1) # 元のデータフレームと連結 df_dummy
OneHotEncoder
sklearnのOneHotEncoderを使えば、同様にダミー変数化してくれます。
from sklearn.preprocessing import OneHotEncoder oenc = OneHotEncoder(sparse=False, dtype=int) oenc.fit(df[['drink']]) # pandas.core.frame.DataFrame型もしくは二次元のnumpy.ndarray型が引数でないとエラー oenc_vec = oenc.transform(df[['drink']]) # numpy.ndarray型で返却される df_oenc = pd.DataFrame(oenc_vec, columns=['coffee', 'cola', 'tea']) df_oht = pd.concat([df, df_oenc], axis=1) # 元のデータフレームと連結 df_oht

LabelBinarizer
sklearnのLabelBinarizerを使えば、同様にダミー変数化してくれます。
from sklearn.preprocessing import LabelBinarizer lbnr = LabelBinarizer() lbnr.fit(df[['drink']]) df_lbnr = pd.concat([df, pd.DataFrame(lbnr.transform(df[['drink']]), columns=['coffee', 'cola', 'tea'])], axis=1) # OneHotEncoderとほぼ同じコードなためワンライナーで記述 df_lbnr
get_dummiesとOneHotEncoder、LabelBinarizerの違い
factorizeとLabelEncoderの違い同様、 学習データとテストデータにデータがわけられているとします。
get_dummisを用いた場合、学習データとテストデータで作成されるカラムの数が異なってしまいます。factorizeとLabelEncoderの違いと同じように学習データとテストデータを連結させる方法もありますが、OneHotEncoderとLabelBinarizerを使えば回避できます。
以下のコードではLabelBinarizerの例です。
lbnr = LabelBinarizer() lbnr.fit(train['drink']) display(pd.DataFrame(lbnr.transform(train[['drink']]), columns=['coffee', 'cola', 'tea'])) display(pd.DataFrame(lbnr.transform(test[['drink']]), columns=['coffee', 'cola', 'tea']))

ただし、データの中にnanもしくはinfが含まれている場合、get_dummisはエラーが出ませんが、OneHotEncoderとLabelBinarizerはエラーが出ます。
oenc = OneHotEncoder(sparse=False) df['nan_and_inf'] = ['A', 'A', 'A', 'A', 'A', 'A', np.nan, np.inf, 'B', 'B'] df

# エラーが出る oenc.fit_transform(df[['nan_and_inf']])
# エラーが出ない pd.get_dummies(df['nan_and_inf'])

nanはスルーされますが、infはされないことに注意です。
OneHotEncoderとLabelBinarizerの違い
OneHotEncoderとLabelBinarizerの違いは複数のカラムをまとめてダミー変数化できるかどうかです。順序尺度データではありますが、sizeデータもまとめてダミー変数化してみます。
# エラーが出る pd.DataFrame(lbnr.fit_transform(train[['drink', 'size']]), columns=['coffee', 'cola', 'tea', 'L', 'M', 'S'])
# エラーが出ない pd.DataFrame(oenc.fit_transform(train[['drink', 'size']]), columns=['coffee', 'cola', 'tea', 'L', 'M', 'S'])

順序尺度
名義尺度とは異なりラベリングが一般的かと思います。しかし、factorizeやLabelEncoderでは任意の順番にラベリングできません。また、色々調べてみましたが、pandas、sckit-learnともに任意の順番にラベリングできるメソッドはなさそうです。
そのため自分で関数なり作る必要があります。以下に例を示します。
apply
lambda式を使えば一行で書けます。
df['ordinal_size'] = df['size'].apply(lambda x: ['S', 'M', 'L', 'LL'].index(x))
map
mapでもlambda式を使えば一行で書けます。ただmapの場合は辞書型もいける口です。ここは個人の好みでしょう。
# df['ordinal_size'] = df['size'].map(lambda x: ['S', 'M', 'L', 'LL'].index(x)) # lambdaもいける df['ordinal_size'] = df['size'].map({'S': 0, 'M': 1, 'L': 2, 'LL':3})
また、自分でカテゴリ変数のリストを作るのが面倒な場合(もしくは多すぎる)は、学習データとテストデータ含めたすべてのデータからユニークな値を取るしかない思います。
unique_size_list = list(all_df['size'].unique()) train['ordinal_size'] = train['size'].apply(lambda x: unique_size_list.index(x)) test['ordinal_size'] = test['size'].apply(lambda x: unique_size_list.index(x)) display(train) display(test)

factorize
一応factorizeとLabelEncoderの実行結果も示します。
sizeの出現順がS、M、Lだったためたまたまうまくいっています。順番があらかじめラベリングしたい順序にソートされていればfactorizeは使えなくもないです。
ft_array, ft_index = pd.factorize(df['size']) # tupple型で返却される df_ft = pd.DataFrame(ft_array, columns=['ft_size']) df_factrize = pd.concat([df, df_ft], axis=1) # 元のデータフレームと連結 df_factrize

LabelEncoder
アルファベット順=ラベリングしたい順序であれば使えます。sizeの例では無理です。
from sklearn.preprocessing import LabelEncoder lenc = LabelEncoder() lenc.fit(df['size']) lenc_vec = lenc.transform(df['size']) df_le = pd.DataFrame(lenc_vec, columns=['le_size']) df_lenc = pd.concat([df, df_le], axis=1) # 元のデータフレームと連結 df_lenc

まとめ
まとめると以下の表になります。
- ○:この手法がベター、もしくはこの手法しかない
- △:この手法よりも良い手法がある
- ✕:この手法は一般的ではない
| 名義尺度 | 順序尺度 | 感想 | |
|---|---|---|---|
| get_dummis | △ | ✕ | 学習データとテストデータのカテゴリ変数に注意 |
| OneHotEncoder | ○ | ✕ | nanとinfに注意 |
| LabelBinarizer | ○ | ✕ | nanとinfに注意 |
| factorize | △ | △ | 楽だが中途半端 |
| LabelEncoder | △ | △ | 楽だが中途半端 |
| オリジナル関数 | △ | ○ | オレオレ関数は最強 |
表から分かる通り、名義尺度はOneHotEncoderもしくはLabelBinarizerを使う、順序尺度はオリジナル関数を定義する、というのが結論です。
参考文献
人工知能プログラミングのための数学がわかる本 | 石川 聡彦 |本 | 通販 | Amazon
Pythonでのカテゴリ変数(名義尺度・順序尺度)のエンコード(数値化)方法 ~順序のマッピング、LabelEncoderとOne Hot Encoder~ - Qiita
One-HotエンコーディングならPandasのget_dummiesを使おう | Shikoan's ML Blog
【python】機械学習でpandas.get_dummiesを使ってはいけない - 静かなる名辞
【python】sklearnでのカテゴリ変数の取り扱いまとめ LabelEncoder, OneHotEncoderなど - 静かなる名辞
pandasでカテゴリー変数を数値に変換する | 分析ノート